When Good Patches go Bad - a DNS tale that didn't start out that way
I recently had a client call me, the issue that day was "the VPN is down". What it turned out to be was that RADIUS would not start, because some other application had port UDP/1645 (one of the common RADIUS ports) open. Since he didn't have RADIUS, no VPN connections could authenticate.
So, standard drill, we ran "netstat -naob", to list out which application was using which port, and found that DNS was using that port. Wait, What, DNS? DNS doesn't use that port, does it? When asked, what port does DNS use, what you'll most often hear is "UDP/53", or more correctly, "TCP/53 and UDP/53", but that is only half the story. When a DNS server makes a request (in recursive lookups for example), it opens an ephemeral port, some port above 1024 as the source, with UDP/53 or TCP/53 as it's destination.
So, ok, that all makes sense, but what was DNS doing, opening that port when the service starts during the server boot-up sequence? The answer to that is, Microsoft saw the act of opening the outbound ports as a performance issue that they should fix. Starting with DNS Server service security update 953230 (MS08-037), DNS now reserves 2500 random UDP ports for outbound communication
What, you say? Random, as in picked randomly, before other services start, without regard for what else is installed on the server Yup. But surely they reserve the UDP ports commonly seen by other apps, or at least UDP ports used by native Microsoft Windows Server services? Nope. The only port that is reserved by default is UDP/3343 - ms-cluster-net - which is as the name implies, used by communications between MS Cluster members.
So, what to do? Luckily, there's a way to reserve the ports used by other applications, so that DNS won't snap them up before other services start. First, go to the DNS server in question, make sure that everything is running, and get the task number that DNS.EXE is currently using:
C: >tasklist | find "dns.exe"
dns.exe 1816 Console 0 19,652 K
In this case, the task number is 1816. Then, get all the open UDP ports that *aren't* using 1816
C: >netstat -nao -p UDP | find /v " 1816"
Active Connections
Proto Local Address Foreign Address State PID
UDP 0.0.0.0:42 *:* 860
UDP 0.0.0.0:135 *:* 816
UDP 0.0.0.0:161 *:* 3416
UDP 0.0.0.0:445 *:* 4
UDP 0.0.0.0:500 *:* 512
UDP 0.0.0.0:1050 *:* 1832
UDP 0.0.0.0:1099 *:* 2536
You may want to edit this list, some of them might be ephemeral ports. If there's any question about what task is using which port, you can hunt them down by running:
taskilst | find "tasknumber"
or, run "netstat -naob" - - i find this a bit less useful since the task information is spread across multiple lines.
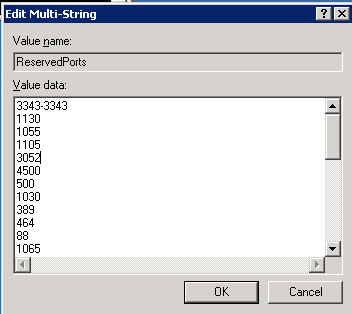
Finally, with a list of ports we want to reserve, we go to the registry with REGEDT32, to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesTcpipParametersReservedPorts
.png)
Update the value for this entry with the UDP ports that you've decided to reserve:
Finally, back to the original issue, RADIUS now starts and my client's VPN is running. We also added a second RADIUS back in - - the second RADIUS server had been built when the VPN went in, but had since mysteriously disappeared. But that's a whole 'nother story ...
If you've had a patch (recent or way back in the day) "go bad on you", we'd like to hear about it, please use our comment form. Patches with silly design decisions, patches that crashed your server or workstation, patches that were later pulled or re-issued, they're all good stories - - after they're fixed that is !
A final note:
Opening outbound ports in advance is indeed a good way to get a performance boost on DNS, if you have, say 30,000 active users hitting 2 or 3 servers. But since most organizations don't have that user count, a more practical approach to reserving ports would be to simply wait for queries, and not release the outbound ports as outbound requests leave the server, until the count is at the desired number. Maybe reserving ports should wait until the server has been up for some period of time, say 20 minutes, to give all the other system services a chance to start and get their required resources. Another really good thing to do would be to make the port reservation activity an OPTION in the DNS admin GUI, not the DEFAULT.
In Server 2008, the ephemeral port range for reservations is 49152-65535, so the impact of this issue is much less. You can duplicate this behaviour in Server 2003 by adjusting the MaxUserPort registry entry (see the MS documents below for details on this)
References:
http://support.microsoft.com/kb/956188
http://support.microsoft.com/kb/812873
http://support.microsoft.com/kb/832017
===============
Rob VandenBrink
Metafore


Comments
mbrown
Aug 18th 2011
1 decade ago
http://blogs.technet.com/b/sseshad/archive/2008/12/03/windows-dns-and-the-kaminsky-bug.aspx
Bryan
Aug 18th 2011
1 decade ago
Joshua
Aug 18th 2011
1 decade ago
From a design perspective though, there's no reason that they couldn't randomize the port selection (and test port availability) at the time of the query though. If reservations are still a requirement, they could even do reservations of the first 2500 randomly selected ports in this way, at the time of the query. I don't see the rationale in reserving the entire port pool when the service starts - it just causes too many problems.
Rob VandenBrink
Aug 18th 2011
1 decade ago
David
Aug 18th 2011
1 decade ago
the issue described by you is documented by Microsoft KB: http://support.microsoft.com/kb/953230
And the main purpose of this patch is to respond to CVE-2008-1447 as pointed by Bryan.
I guess you just missed to test the patch and read the KB before apply it.
Paulo Oliveira
Aug 18th 2011
1 decade ago
The real issue is the CHOICE of ports, and compliance with relevant standards. First of all, 1648 is not in the ephemeral port number; 1648 is a registered port, meaning, no application other than one implementing the IANA registered protocol for that port number should be binding that reserved number.
Ephemeral ports range from 32768 to 65535, and any port number in that range is fair game.
Instead of the DNS server being modified to have a random selection for ephemeral ports, the OS itself should be modified, so _every_ selection of an ephemeral port is random, but within the allowed range.
Instead of binding 2500 ports in advance, a small number should be bound, and the DNS server should adapt the number of pre-bound ports based on its query load.
In most environments, a windows DNS server will handle no more than 20 or 30 queries per second, but bound ports consume shared network resources.
Mysid
Aug 19th 2011
1 decade ago
Unless it was only just installed at the client, in which case this article should probably be about the hazards of not patching 36 month old DNS flaws...
Genima
Aug 19th 2011
1 decade ago
John Hardin
Aug 19th 2011
1 decade ago
Well, good thing 2003 is EOL in a couple years. Everyone's on top of that, right? ;)
KungFooChef
Aug 19th 2011
1 decade ago